

Neuronales Jahrhundert :Neuronale Netze haben das künstliche Sehen und die automatische Spracherkennung revolutioniert. Diese Revolution des maschinellen Lernens ist auch im Bereich der Spracherkennung vielversprechend. Entdecken Sie, wie Acapela sich weiterentwickelt, um die Stimme zu erzeugen, die Sie brauchen.
Unser Forschungs- und Entwicklungslabor hat Acapela DNN entwickelt, eine Maschine, die in der Lage ist, mit einer begrenzten Anzahl von Sprachaufnahmen personalisierte Stimmen zu erzeugen.

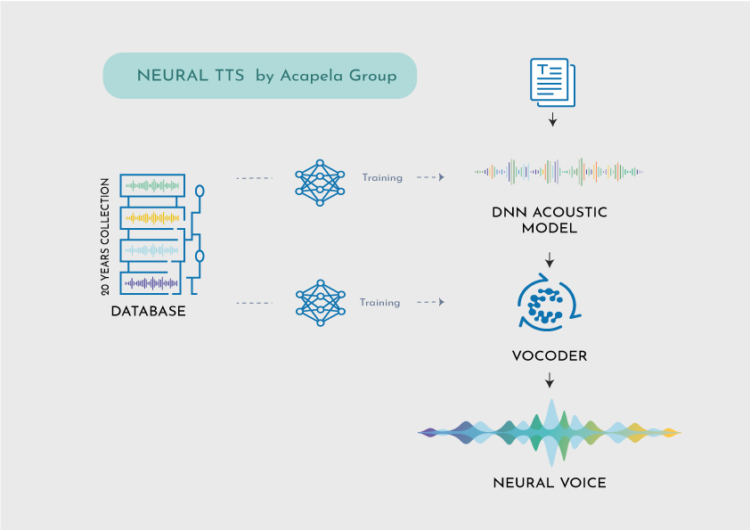
WAS IST DNN?
Ein deep neural network (DNN) ist ein künstliches neuronales Netzwerk (KNN) mit mehreren versteckten Schichten zwischen der Eingabe- und der Ausgabeschicht. DNNs können mit Hilfe von Technologien des maschinellen Lernens komplexe nichtlineare Beziehungen modellieren. Wir verwenden sie in Text-to-Speech, um die Beziehung zwischen einer Reihe von Eingabetexten und ihren akustischen Realisierungen durch verschiedene Sprecher zu lernen.
Neuronale Netze sind eine Reihe von Algorithmen, die darauf ausgelegt sind, Muster zu erkennen. Sie interpretieren sensorische Daten durch eine Art maschinelle Wahrnehmung, indem sie den rohen Input etikettieren oder clustern. Bei den von ihnen erkannten Mustern handelt es sich um numerische Muster, in die alle Daten der realen Welt (Bilder, Töne, Texte) umgewandelt oder interpretiert werden.
Neuronale TTS können anhand einer großen Datenmenge trainiert werden, um die komplexen Muster der menschlichen Sprache, wie Intonation, Rhythmus und Betonung, zu lernen. Dadurch kann es eine sehr natürliche und ausdrucksstarke Sprache erzeugen, die der menschlichen Sprache sehr ähnlich ist.
WIE FUNKTIONIERT DAS?
Acapela DNN wird offline (unter Verwendung großer GPU-Infrastrukturen) mit all den vielen verschiedenen Stimmen in unserem Katalog trainiert. Wir füttern es mit allen Text- und Akustikdatenbanken, die wir für alle unsere Stimmen haben. Das bedeutet, dass Acapela DNN eine Menge über die menschliche Sprache im Allgemeinen weiß, aber noch nichts über die Stimme einer bestimmten Person weiß und diese Stimme eine Weile hören muss, bevor es sie reproduzieren kann.
- Algorithmus des ersten Laufs: Extraktion von “Voice ID”-Parametern, um die digitale Signatur (oder Sonorität) des Vokaltrakts des Sprechers zu definieren
- Algorithmus des zweites Laufs: Acapela DNN zusätzliches Training, um den Abdruck der Stimme mit ihren feinkörnigen Details (Akzente, Sprechgewohnheiten usw.) abzugleichen Acapela DNN additional training to match the imprint of the voice with its fine grain details (accents, speaking habits, etc.)
Acapela DNN profitiert von unserer Sprachkompetenz und dem Lernen aus unseren umfangreichen Stimm- und Sprachdatenbanken, um Stimmidentitäten zu modellieren und Stimme in vielen Sprachen zu reproduzieren. Das ist viel mehr als die Verkettung von Sprachaufnahmen aus dem Studio, wie wir es mit der Unit Selection und früheren, aber weit verbreiteten Technologien tun.
In speziellen Fällen, wie z. B. bei der Stimmersetzung für Patienten, kann Acapela DNN mit einigen Minuten Sprache arbeiten. Das erreichen wir für Patienten mit my-own-voice, einer Voice-Banking-Lösung (Innovationspreis auf der CES 2023), die es sprachbehinderten Menschen ermöglicht, mit einer digitalen Kopie ihrer Originalstimme als synthetische Stimme weiterzusprechen.
Für die professionelle Nutzung, z. B. die Erstellung einer kundenspezifischen Stimme für das Voice Branding, die Ihnen beim Autofahren die Navigation erleichtert, beim Pendeln Echtzeit-Informationen über Fahrgäste liefert oder Ihrem Avatar in Ihrem Lieblingsspiel eine Stimme verleiht, werden mehr Aufnahmen benötigt. Je mehr Daten vorhanden sind, desto mehr kann das DNN aus bestimmten Gewohnheiten lernen und eine Stimme erzeugen, die dem Original entspricht. Diese Stimmen von höchster Qualität ermöglichen eine realistische, lebensechte Audioausgabe und setzen einen neuen Standard für natürliche Interaktionen in Echtzeit für ein fortschrittliches Benutzererlebnis.
“Die ersten Ergebnisse der Forschung im Jahr 2017 waren beeindruckend. Wir haben an Sprachaufnahmen von bekannten Menschen gearbeitet. Wir haben auch Stimmen für Personen erstellt, die aufgrund von Operationen oder Krankheiten nicht mehr richtig sprechen können. Sie waren die ersten, die mit Stimmen sprachen, die mit Acapela DNN erstellt wurden. Der Erstellung von Stimmen auf der Grundlage dieser neuen Technologie sind keine Grenzen gesetzt. Acapela nutzt jetzt seinen unvergleichlichen Bestand an Sprachdatenbanken und sein über die Jahre erworbenes Fachwissen, um die Grenzen der Technologie zu erweitern und jedem eine Stimme zu geben”, fügt Remy Cadic, CEO der Acapela Group, hinzu.
Wir arbeiten mit Sprecher-Embeddings, um die Stimme zu modellieren. Unsere Modelle erfassen die wichtigsten Merkmale und Eigenschaften der gesprochenen Sprache. Sie werden auf großen Datensätzen von Sprachressourcen trainiert. Der Einsatz dieser neuen Technologie eröffnet dem TTS-Markt und der Acapela-Gruppe große Perspektiven. TTS-Stimmen und -Sprachen von sehr guter Qualität können mit wenigen Samples eines Sprechers entwickelt werden, und die Entwicklung neuer Sprachen und Stimmen wird einfacher, was zu einem Angebot führt, das mehr Auswahl und Vielfalt für alle Nutzer bietet.
DIE LANGE REDE KURZER SINN
Die Geschichte der TTS-Technologie begann mit der allerersten sprechenden Maschine (1779), die von dem ungarischen Erfinder Wolfgang von Kempelen entwickelt wurde (…) Dann begannen Innovationen in den frühen Tagen der Computertechnik durch Bell Labs in den 50er und IBM in den 60er Jahren, den Weg für die Sprachtechnologie zu ebnen. Formant- und Diphon-Technologien brachten wichtige Verbesserungen, bevor man in den 90er Jahren zur Einheitenauswahl überging.
Die Ära der Künstlichen Intelligenz (KI) ist nun dabei, ein neues digitales Zeitalter mit maschinellen Lernfähigkeiten und neuronalen Stimmen zu gestalten. Bei Acapela Group sind wir seit 30 Jahren tief in diese Technologie involviert. Gestützt auf unsere jahrzehntelange Erfahrung und unser wertvolles linguistisches Wissen wollen wir Stimmen schaffen, die den Unterschied ausmachen. Dies führt zu einer kontinuierlichen Entwicklung hin zu einer personalisierten, lebensechten Sprache und einem besseren Zugang zu Technologie und Informationen für alle.
Benötigen Sie weitere Informationen für Ihr Sprachprojekt?
Book a demo