

‘Acapela Group is a bespoke player in speech solutions. For decades we have been creating well known synthetic voices used by visually impaired users. Accessibility issues are very important to Acapela and we work hard to make communication much easier for people with sight, speech and cognitive disabilities’ says Lars-Erik Larsson, CEO of Acapela Group. ‘For years we have been receiving requests from users or their relatives and until today the only answer we could give was ‘’we are working on it’’. We are very proud today to announce that we have created a service to meet this specific, crucial need. We know that once diagnosed the user doesn’t have much time to capture the essence of their voice before losing it. Our goal was to develop the most convenient service for them to use, while ensuring that all the sounds we need to create a synthetic version of their voice could be recorded. My-own-voice is a first step for us in the field of speech impairment. We look forward to developing further innovative solutions to help improve the lives of users,’ he adds.
The recording process
To allow individuals to capture their own voice, the first challenge for our R&D team was to create an entire, whole new process to enable recordings to be made by non-professional speakers, without any help from Acapela linguists, but with the support of the user’s speech therapist. Our expert knowledge had to be harnessed to an end user approach. It has worked out well. We have already run a couple of trials with users about to lose their voice. We have created the foundation for major progress for speech impaired people and we are working on improving methodology and tools to take this vital work forward.
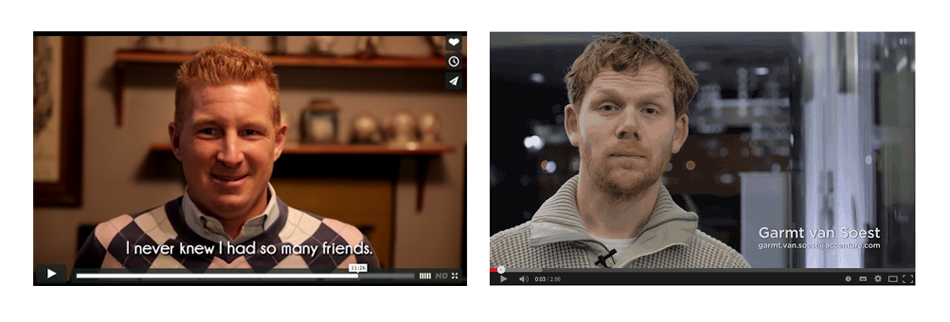
Meet Eric and Garmt,
the pioneers of ‘my-own-voice’
Eric and Garmt have both been diagnosed with ALS. They have decided to create their own synthetic voice and have participated as pioneers on the first ‘my-own-voice’ experiences.
Text-to-speech literally transforms any written input into an audio result. It means that ‘my-own-voice’, based on the recordings of a corpus of various texts, will be capable of speaking any text, as any synthetic voice can do.



